And me.
Fair warning; this post is a bit of a brain dump on my experience with AI code assistance and Cursor and it probably won't age well :p Ok let's go.
Copilot
A few years ago "GitHub Copilot" was introduced. Not to be confused with the recent Windows branding of Copilot, although they're probably running on similar/shard infra. But I want to focus on coding here.
Copilot never really tickled my fancy. It was nice for what it was and I've seen some cases where it produced some amazing predictions. But in the end it was still too limiting and too slow for me. Plus, I was on Webstorm and it did not compel me to jump to vscode.
LLM
Enter the era of LLM. I guess chat, image gen, and code assistance are some obvious usages for this tech.
And even though LLM's are ultimately "next character prediction" engines, they're pretty good at that. Turns out this is true about coding as well. But I think it's not as glamorous as some want you to believe. Obviously, it can do some cool stuff. And with the right prompt and the right tweaks you can get pretty far. But once you get into the nitty gritty there are some pretty steep cliffs on that happy path.
Cursor
A few weeks ago I started a Cursor trial. People were talking it up and I wanted to see what the big deal was.
I started two greenfield projects in Cursor, both in Rust. One would be the backend (CLI) for a special chess game. The other would be an adapter for a JS parser backed by Tree-sitter, a parser generator.
Fwiw, this experience was with "Claude 1.5" in Cursor. If you're from the future (so like, next year) and you're like "eh, what is that"; "Claude" is pretty much the top of the line in terms of code assistance LLM right now. Far ahead of its competitors and not something you can currently run on consumer grade hardware.
Additionally, as I learned later, Cursor runs a bunch of small AI networks to do various tasks in the IDE, like applying a diff or auto complete. For example: its (proprietary) auto-complete is the big selling point here. Miles ahead of GH's copilot.
There's three major things to cover here. First the learning curve in general, second the experience trying to setup JS parsing, and third the experience of writing a chess-based game.
Learning curve
One of the first things I had to bootstrap was the cognitive dissonance between the LLM and the editor. It's very natural to talk to the LLM and expect it to somewhat understand what you want. Not in the least because the response makes you feel like it does. The problem here is that the LLM is not "aware" (using that term lightly here) that it's running inside an IDE. So when you ask it to update some index.html file with your request, and you haven't included that file in the prompt context, then the LLM will tell you "create this file and apply this change" rather than just do it.
What follows is a back and forth between you and the LLM. You'll tell it that the file exists ("It's right there!") and that it should just update the file. Before you realize at some point, right, it doesn't actually know anything about the IDE it's running in. The "system prompt" includes instructions for a pseudo DSL (a custom syntax, if you will) and its response is interpreted as such by the IDE. So when the LLM suggests a change, it's instructed to craft that in a very particular way. The IDE picks this up and applies that part as a diff in the editor. You can actually see it go off the rails a bit in very long sessions, probably because the context has grown so big and cluttered that it kind of forgets the system prompt. Very fourth wall breaking. Also a sign that it's time to restart the chat session.
I find this DSL approach very smart and makes a lot of sense. However, initially that's not obvious as a user.
The inclusion of files as part of the context is a must. I feel the UI was a bit lacking here. For example, once I learned I could use
@ to include a whole folder it took away some frustration of starting new chat sessions. Of course, files do increase the prompt size implicitly. But that's not something that's obvious until you start long debugging sessions because the prompt size and/or limits are not explicitly shown anywhere.There's a few things the LLM does well and then there are limits. Learning where the limits of code generation are is important. At the time of writing, the dissonance of the LLM includes not seeing what you see. In particular, when your IDE (Cursor uses a customized fork of VSCode) shows a bunch of warnings and errors, the LLM does not actually see any of these. So asking it to solve the reported problems only works by a fluke of the LLM being able to find the already reported issue by looking at the code, not because it analyzed the reported issue messages. It's an important distinction and limitation. I expect the IDE will soon have an easier way of connecting the dots here, though.
Copilot on steroids
Similarly, the Cursor auto-complete is awesome. It's really good. It compelled me from switching from Webstorm (after 10+ years of professional use!) to their VSCode fork. After a two week trial!
And because it's so good, it adds to the dissonance because it doesn't actually understand what it's doing. It just appears to understand.
Sometimes it will make suggestions that make total sense. For example, in the chess game it'll try to be semantic and offer semantically correct auto-completion for chess piece names or square coordinates. But in the end it's also basing its prediction on what you've been typing and so it might suggest an invalid piece of code (semantically or even syntactically) just because it matches the pattern of what you were writing elsewhere. It can write tests for chess moves just fine but it will also easily hallucinate correct moves and/or situations.
That said, it's very good contextually. I think there's a trick going on with copying text as it's very often spot on with predicting the next thing to type when you copy something form one file and click anywhere in another file.
It (the auto-complete specifically) has an obvious context windows of about 4 lines of code. But the tab completion makes that a pretty good experience. There's absolutely room for improvement and I'm pretty sure they'll address related issues. Right now it's just already so much better than what I've seen from copilot. And this matches what I'm hearing from other people around me.
As an aside, I think we should consider repurposing the caps-lock key to be the AI completion key. I sometimes find myself fighting the IDE to just indent without completion.
The parser
Ahhh, writing parsers. You might know I've spent quite some time of my life in the parser world.
In this case I had to set up a project that would parse JS/TS and create an AST that we would then process further. For reasons beyond this blog, the request was to use Tree-sitter, a parser generator, as the parser. This does not produce an AST in the classical sense so I wanted to convert it to an ESTree like AST first.
When you ask Claude to set up a JS parser it defaults to SWC. However, it will happily switch to OXC (apparently you're not supposed to say "oxi" but I can't not) when asked for that though. And again switch to Tree Sitter. But the code generation wasn't smooth for me and it took me a bit of fiddling and prodding before it would produce rust code that would parse JS and dump whatever AST it resulted in. I think that's in part due to outdated third party library version information.
See, just like humans a network has to learn about stuff before it can tell you things. If you want to use a feature that was released last week then an LLM that was trained on data two years old can't possibly tell you anything about it. I know it's all about predicting stuff but it won't predict the future :p Well, not reliably anyways.
Once I had a stable baseline version to convert the Tree-sitter output to something that looks like ESTree (somewhat of a standard AST for JS code). This is where Cursor shined. It was so good at predicting the nodes I wanted to create. Probably in part because it knew all about ESTree. So knocking out those 30-40 unique nodes was fairly easy and many tabs were pressed along the way. This repetitive nature is great to do in Cursor.
That said, you still had to be aware of what the auto-completion generated. For example, in Tree-sitter you have "named" and "unnamed" nodes. And the generated code would always default to unnamed children, even when it "clearly" needed to fetch the named child. All the previous nodes would use this but when creating new nodes the auto-completed code would still default to unnamed children. So that can be a little annoying. But nothing that tab completion won't fix for you after a tiny hint by you. Maybe it's just an example of different networks at play.
The chess game
Okay, so now for something completely different. I wanted to write a special kind of chess game. This game would start as a regular game of chess and I wanted to add new pieces to it with special behavior, later.
Again, it was easy to create the chess game. Including the concept of "bitboards", a common technique to represent chess states in chess engines. It semantically understood the difference between what a knight could do versus what a pawn could do. That sort of stuff is trivial for it.
When it came the point where I wanted to add custom pieces, like a "King Midas" or a "Centaur", that was also fine! :D Although auto-complete was clearly more error-prone, it was no big deal.
Here's what the CLI output would look like after a few weeks of working on it on-and-off:

This would be written to a terminal. The next step is to turn this into an api-server and have a web front-end fetch and show this data properly. But first we need to consider some art.
Art gen
The CLI of the game wasn't very demanding in terms of art but the frontend would be. So I started to experiment a bit with trying to generate the kind of art that I wanted to have in my game.
My machine is relatively old, with an 8gb nvidia 3070. But that still allows me to run some of the mainstream consumer models. I was able to play a bit around with Stable Diffusion, 1.5, 2.0, SDXL, Flux.
Without doubling the size of this post on that subject, here are some take-aways on that.
Quality
You can absolutely generate stunning images on local consumer hardware. That said, I think you can generate even better and more detailed material with online models. Similar to how you can't run Claude 1.5 locally and how it blows local models out of the water.
I haven't paid for any image gen yet so my experience is mostly free tier / local.
I noticed that the default models have a harder time generating images with low resolution, which I was aiming for with pixel art. It's kind of interesting because I would expect smaller images to be easier. But perhaps the diffusion approach simply works better on bigger images, even though it takes longer to generate. That makes it seem like quality is bound to time but in this case it's more basic than that.
Of course, quality is affected by how many iterations it does. So that's a direct time-quality relationship for sure.
Ability
One thing that took me a bit by surprise is how it's able to put a kitten on the moon with relative ease, but it's very difficult to generate a generally accepted concept like a Centaur (a mythical being half-human half-horse). The local models I've tried almost refuse to generate it, ending with either a horse or a human. The free online models I've tried were a bit hit-or-miss. Higher end models seemed to be easier to prompt for a Centaur.
This is offset by a myriad of available "lora's" which are like plugins for your image gen and are trained on a particular topic.
Mind you, this makes perfect sense. It cannot show you an image concept it was never taught. So if the training set does not know about centaurs then it's difficult to paint a centaur. But even if it knows a bit about centaurs, it seems to be more biased towards showing the human or horse. I'm guessing that's just because there are more training images of either outweigh the number of centaurs. But the point is: it doesn't seem to "know" how to mix those concepts out of the box.
This problem is exacerbated by the way prompting works in these image gens: they're more keyword bound than human text. So while you're definitely going to try and write "kittens on the moon", and it is probably going to show you something in that ballpark, you're more likely to get what you want by adding a bunch of rather specific keywords to hit the sweet point in the network's latent space (aka its memory). There's a learning curve waiting for you.
Here are some attempts at centaurs with various free services:




All that said and done, it's definitely possible to generate some nice game art for your game. It will also take you a small life time to find the right circumstance under which the images get generated.
Claude the artist
After generating a bunch of sweet pixel art examples of chess pieces I wanted to work on the frontend of the game.
I had generated some pixel art and in my head I was jesting with an idea of generating chess pieces as voxel models. But I figured that would be way too much work to setup just to try.
As a bit of a bluff more than anything else I wanted to see how far Claude would get with that.
Holy smokes, it did not disappoint.
Claude created a vanilla WebGL renderer for voxel models from scratch. The models were represented as flat arrays of rgba bytes (which was the request). Took a few corrections to get the camera right and model centered but in two hours I had a working demo. Wow.
And that's not all! It was actually able to generate example voxel models for the chess pieces. Both the classic pieces and the special ones! The models were procedurally generated so it did not generate a list of rgba ints, rather it generated code that would generate the model. That may actually be even more impressive.

Or have a look at the actual WebGL demo! :)
So I had a basic vanilla WebGL based voxel renderer up and running and some sample models. The models aren't the best looking, there's no denying that. But at the same time, considering how they were made I found it all extremely impressive.
It took me another day to get the refine the models a bit. I would ask Claude to add shading to the models and add more details. It would happily take an existing model (one of the procedures it had written before) and iterate further on it. This kind of makes sense insofar that this is what LLM's are being hyped about: understanding your code base. But it's still dang impressive. Look at the current status of the models and compare it to the earlier version above.

At the same time, when I ask it to create a voxel model for a Centaur chess piece, it actually creates one!
As a bonus, here's a crumbling effect that it easily whipped up for me:
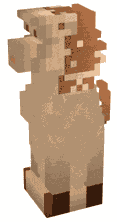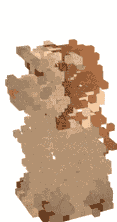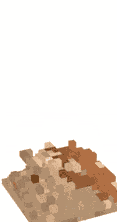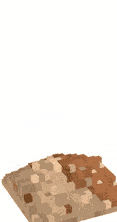
It's not a destruction kind of game but it does make me want to build one :p
One thing I noticed is that at some point during the modeling the results would suddenly be extremely bad. It's as if it was a completely different network, inferior to Claude, giving the answers. The UI had no indication of this happening. Responses were simpler and in particular the modeling work that I was doing right there and then would suddenly have significantly worse results. It corrected itself later that night.
Another thing is that it would sometimes make unrelated changes, commonly dropping comments from the code. It would sometimes arbitrarily start to use ES6 modules rather than plain script tags in global scope, and sometimes it would randomly pull in ThreeJS. Otoh, it did refer to an external open source script for a small matrix computation library when it needed that.
These kinds of changes are no big deal on their own; you have to change your prompt to tell it not to do this and it won't. But when you're debugging it will keep on making the same mistake in the same chat. That can get a bit annoying. Talking about long chats...
Debugging
One last topic I'll cover is debugging with a code assist. With Claude in this case.
The WebGL renderer worked but not without some issue. The voxel would but cut off at some arbitrary point, without a clear pattern or reason for it. And no errors either. Voxels just stopped being rendered after some count.
Turns out this was due to a limit in WebGL 1.0 on the number of vertexes being drawn in a single draw call. That took me about a day of debugging (I'm not a WebGL whiz and did not know). I had to restart the session three or four times because Claude would basically go in a loop and end on a dead end. But every time I'd see a small piece of the puzzle and ultimately I was able to guide it to realize what was going on.
These sessions showed some deeper problems that the code assists currently have, mainly around "context". In this context, the "context" of an LLM is the complete input (or prompt) that an LLM receives and on which it bases the output. Invisible to the user, this context includes the contents of files you included, your previous messages (prompts) of the current conversation, and the LLM's output in response. As you can imagine, in a debug session of about two hours this context can grow quite dramatically. Especially after pasting in verbose stack traces or after enumerous LLM suggestions.
That's definitely a nice thing though: you can paste in a stack trace or bunch of verbose error messages (looking at you TS or Rust) and it will just understand what the problem is.
At some point it gets slower in response, which slows you as engineer down as you're waiting for an answer too. This may be less about the LLM and more about the IDE and/or transport. Not sure. Either way, it definitely gets slower after a large session.
Inevitably you may exceed the max context size, at which point you can only go back to an earlier checkpoint or restart the session full. This also means the LLM forgets anything past that point. So one trick is to ask it for a prompt like "give me a prompt to bring you up to speed with what you've discovered so far".
Debugging without screen sharing
One other thing I found interesting is how debugging a visual app like WebGL with an LLM is really like pair programming with somebody remotely without being able to share your screen.
When trying to figure out this partial WebGL render I would describe it what it saw. Or it would add logs to the code and I would paste the logs back to it. Based on that it would suggest more code changes, simplifying the scene or debugging more output, to the point of spinning a single box. Then shading the box in rainbow. And I would explicitly explain what I would see on screen. It would keep iterating on that until at some point it had found the problem (in session three or four). Of course at that point it had trashed the input and I was only saved by my git stash, not the Cursor editor (important lesson here!).
I probably could have made a screengrab of the canvas and pasted that back into Claude as feedback instead, though I'm not sure if Cursor supports that.
Conclusion
What can I say; I ditched Webstorm in favor of Cursor after a two week trial and am now a paying customer.
The world of LLM's is moving extremely fast right now so what's hot and happening right now will be outdated next year. Next month.
Am I afraid it will take over my job? No. Not in the slightest.
Will it be able to do this in due time? Maybe, I'm not gonna say it can't. With enough context, up to date knowledge, and feedback ... yeah I think it can cover more complex applications. Right now that's definitely not the case.
Is it helpful to a coder? That depends, actually. While I'm sure a junior or non-coder can get far on a poc, it will still require the background knowledge of a programmer to get to a stable end product. To figure out where the assistant goes off the rails. To validate that what it writes is sound. To do code review.
The things Claude can do are great but in its current form it is limited quickly. I'm fine to have it greenfield some project but to just modify a complex app on the fly depends on whether I can feed it enough context of the code base to just fix it. And then it depends on library versions used, API's, code style, etc. And even then, the onus is still on you the developer to do the code review. Which is harder because you didn't actually write the code. That's a concern in Rust but that's a bigger concern in something like JS (or even TS) where the typing system may not catch you.
The code assist makes you lazy. You're more prone to ask the LLM to fix a little thing where you would have been faster just tweaking the number manually. Or you're fine to accept code that seems to work, without fine tuning it. When the code change is too large, you might be tempted to skim the code review and accept it, leading to bugs and maintainability down the road. Or simply not knowing what the code actually does.
I'm definitely bullish on the future of code assistance. I mean, it only gets better from here, right?